二值类别变量相关性分析
目前,在相关性分析领域,主要使用的技术指标有pearson相关系数、spearman相关系数、kendall相关系数。三者有一个共同的特点,它们都是通过两组数据的元素大小来刻画相关性,也即同增同减的性质。在分类、聚类领域中,为了弥补上述相关性的不足,科学家将距离、方向引入相关性的刻画中,常用的指标有欧式距离、夹角余弦等。虽然这些方法在分类和聚类过程中表现良好,但是它们任然有局限性,这种局限性表现为它们能区分类别变量却不能计算类别变量数据间的相关性。即距离、方向刻画的是总体级的相关性质而不能刻画样本级的相关性。
为了研究类别变量与数值变量间的相关性,研究人员大量使用列联表分析,如用eta系数来刻画。对于类别变量与类别变量之间的相关性,借助于列联表,我们可以计算斯皮尔曼等级相关系数与G系数、Gamma相关系数、d系数来刻画。
对于0、1型数据序列集,求解其相关性,我们可以从类别的聚集程度度量。两组序列间的区分度越极端,序列间的相关性就越大。如:将两个序列聚集到一起,组成数对,如果0全来自序列1,1全来自序列2,那么两个序列的区分度最大,此时序列之间是强相关的,我们可以认为部件2处于状态1时,部件1处于状态0,相关性为-1;反之,聚集之后数据全是1或全是0,那么序列间没有区分度,同理,此时序列间是强相关的,相关性为1。为了研究这种区分度,我们引入示性函数进行表示。若令X表示部件1,Y表示部件2,则用 I(Xi=Yi) 表示序列间相等的个数,用表示 I(Xi![]() Yi) 系列间不同的个数。当数据最混乱的时候有 I(Xi=Yi) = I(Xi
Yi) 系列间不同的个数。当数据最混乱的时候有 I(Xi=Yi) = I(Xi![]() Yi) ,若有n组数据,则有 I(Xi=Yi) =n/2。我们用下式来度量这种区分度:
Yi) ,若有n组数据,则有 I(Xi=Yi) =n/2。我们用下式来度量这种区分度:
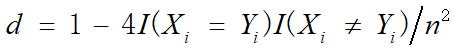
这种区分度取值是0到1,这里并不能表示负相关这种情况,为了让它可以用于相关系数的度量(相关系数一般取值(-1,1)),我们在d的前面在乘一个示性因子,如下式所示:
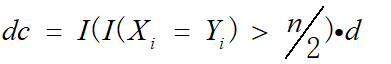
其中dc为两个序列间的相关系数。
下面我们通过一个案例和python代码,实际展示效果。
1、数据准备
我们在csv文件里先准备好几列0、1型的数据,如下图所示:
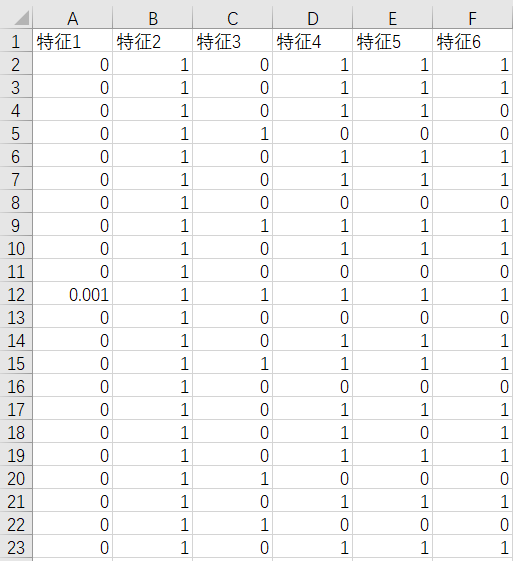
这里我用的是csv文件,当然也可以使用其他数据格式,为了方便,请使用pandas可以直接调用的.
2、python代码实例
1 mport pandas as pd 2 import numpy as np 3 4 5 class DC: 6 7 def __init__(self, pd_data): 8 self.data = pd_data 9 self.n = pd_data.shape[0]10 self.columns = pd_data.columns11 # self.columns = (pd_data.columns.shape[0], )*212 13 def out_matrix_initialization(self):14 data_frame = pd.DataFrame(columns=self.columns, index=self.columns)15 return data_frame16 17 def _get_col(self, index1, index2):18 return [self.columns[index1], self.columns[index2]]19 20 def get_class_correlation(self, index1, index2):21 i, j = self._get_col(index1, index2)22 equality = np.sum(self.data[i] == self.data[j])23 24 # sign_value = 1.001**(-equality * (self.n - equality) / self.n ** 2) - 1.001**(-1 / 4)25 # res = sign_value / (1 - 1.001**(-1 / 4))26 across = equality * (self.n - equality)27 # print("index1:{}, index2:{}, across:{}".format(index1, index2, across))28 res = 1 - 4*across / self.n**229 res = res*np.sign(equality / self.n - 0.5)30 return round(res, 4)31 32 def get_matrix(self):33 result = self.out_matrix_initialization()34 raw, col = result.shape35 for i in range(raw):36 for j in range(col):37 result.loc[i:i+1, j:j+1] = self.get_class_correlation(i, j)38 return result39 40 41 if __name__ == '__main__':42 data = pd.read_csv("test.csv")43 dc = DC(data)44 s = dc.get_matrix()45 print(data.corr())46 print(s) 3、调用结果截图
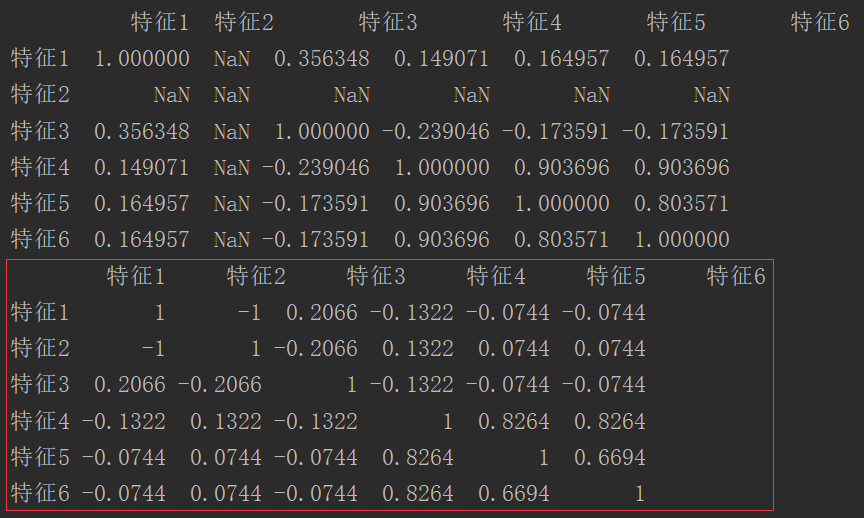
方框内是我们自己定义的dc相关系数,而上面的是Pearson相关系数,明显在这里变量为类别变量时,Pearson相关系数不能很好地描述相关性,由于其在理论是是描述变量的大小的,而类别变量没有大小之分,只有类别之分,所以在这里使用它有理论上的错误;并且在数据类别全部相反的时候,Pearson直接为NaN,无法计算,而dc系数可以很好地描述出这种完全负相关的情况。
4、总结
这里的dc系数适用于二值变量,如果是多类别变量,它同样会失效,关于dc系数如何推广到多类别变量间的相关性度量,还有待讨论。
有什么问题欢迎留言指正!
转载、调用请注明出处!